

Vercel云函数的缺点和我的改进方案
上一节我们做了一个基础的文件操作服务,使用Next + Vercel部署。我通过后续文档发现,Vercel的云函数有一些限制:
- 临时文件访问限制。过期会自动删除,这个倒是没关系,因为文件转换器本来就是删掉临时文件的
- 依赖包的限制。sharp 等文件操作库依赖原生模块(Native Addons),导致编译不通过
- 边缘计算(Edge)的限制。Edge Runtime 完全禁用
fs、path等模块,仅支持有限的 Web API,文件操作需要进行流式处理重构
那么这种情况下利用Vercel的云函数做Serverless就不再合适了。
当下流行的方案有 Supabase ,Supabse是一款开源的后端即服务(Baas)、提供完整的数据库能力(基于Postgresql)、开箱即用的后端服务(OAuth、对象存储)、AI应用协同。作为初创企业是不错的。
这里我使用的是Hono.js作为后端服务,Hono.js可以集成多种运行时(Bun、Deno、Vercel等),在设计上注重极简主义(这点我很喜欢😊),工程上注重边缘计算、Serverless等实现。
集成Hono.js和结构分层
决定了替代方案之后,我们的文件目录也需要调整,以便于后续开发
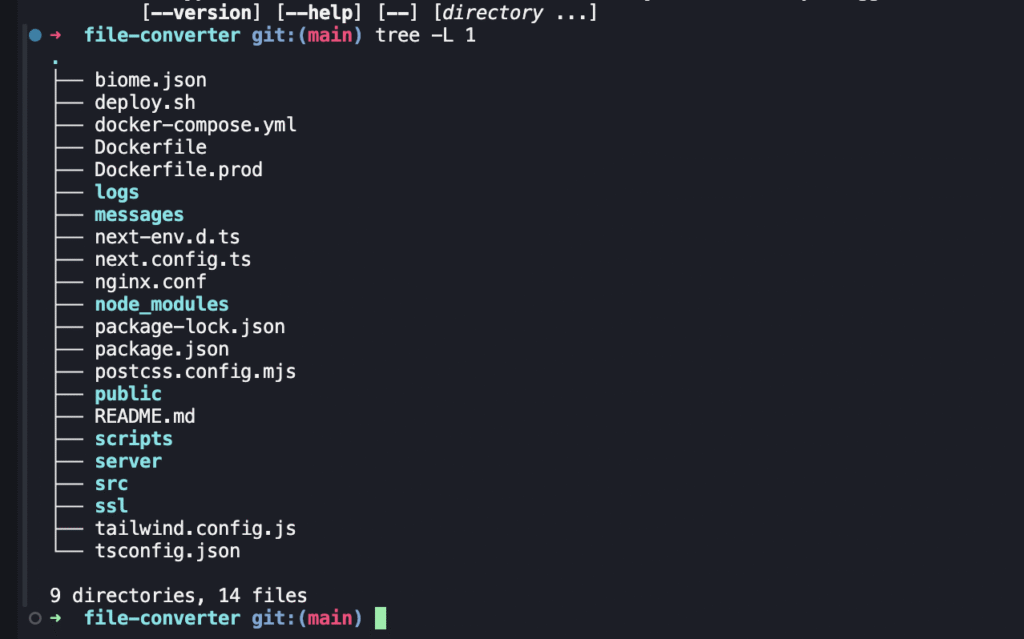
这里我们重点关注 src 、 server 、messages 三个结构目录;因为不用Vercel提供的服务器了,所以我们也需要准备Docker和Nginx在自己的云服务器上,这节我们先不讲部署相关的内容。
- server 后端接口
- src Next前端页面(同原来)
- messages(i18n多语言配置,用来存放语言文件)
接下来看一下server的结构目录吧
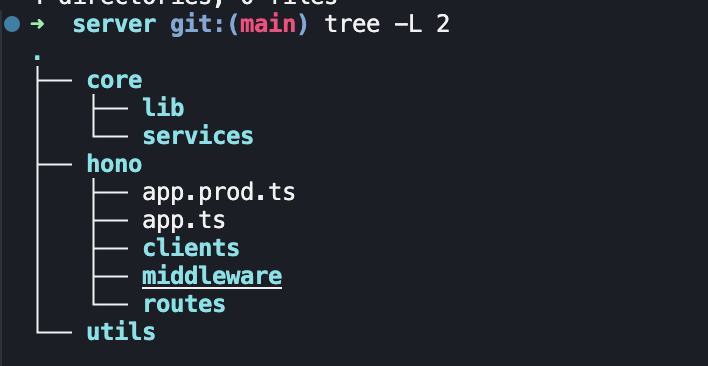
三个目录的作用如下
- core 核心代码,services同大多数后端架构一样,存放业务逻辑
- hono 存放路由、中间件过滤器等等
- utils 存放工具函数
接下来我贴一个粗略的网络请求流程图,后端的同学对这个很熟悉,可以酌情跳过,后续讲解从流程图的顺序开始描述对应的文件
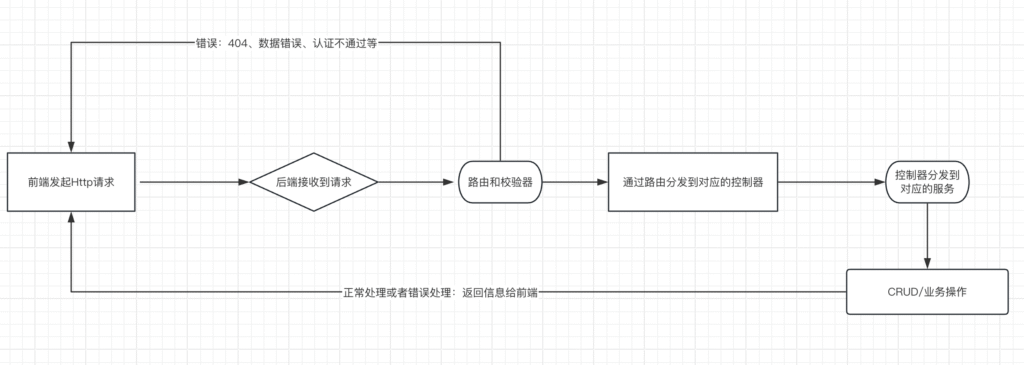
“接收请求”“路由和校验器”这个步骤是在/server/hono/app.ts 下进行的,接收到了请求之后,配合middleware进行鉴权、Validate等处理;这里我为了简化业务流程,middleware文件夹先空着;
app.ts是后端服务的起点(这里和src路径下的前端app.ts不一样,虽然会同名,但是不是同一个东西)
app我增加了一个.prod的文件,适用于在生产环境下启用的。
// 生产环境启动文件 app.prod.ts
import { Hono } from "hono";
import converter from "./routes/image-converter/index";
import { cors } from "hono/cors";
import hello from "./routes/hello/index";
import cleanup from "./routes/cleanup/index";
import { serve } from "@hono/node-server";
import { CleanupService } from "@server/core/services/cleanup.service";
const app = new Hono().basePath("/api");
app.use("*", cors());
app.route("/converter", converter);
app.route("/hello", hello);
app.route("/cleanup", cleanup);
app.get("/health", (c) => c.text("OK"));
const port = Number.parseInt(process.env.HONO_PORT || "3001", 10);
const server = serve(
{
fetch: app.fetch,
port,
hostname: "0.0.0.0",
},
(info) => {
console.log(`Hono服务运行在 http://0.0.0.0:${info.port}`);
// 启动定时清理服务
const cleanupService = new CleanupService();
cleanupService.startCleanupService();
},
);
// 优雅关闭
const gracefulShutdown = (signal: string) => {
console.log(`收到 ${signal} 信号,开始优雅关闭...`);
server.close(() => {
console.log("服务器已关闭");
process.exit(0);
});
};
process.on("SIGINT", () => gracefulShutdown("SIGINT"));
process.on("SIGTERM", () => gracefulShutdown("SIGTERM"));
export default {
port,
fetch: app.fetch,
};
10-33行:已经启动了服务了,已经能够根据路由进行匹配,如代码所示,会寻找routes/下的路由,Hono里控制层不会进行明显的分层,简化了步骤。
30-31行:服务启动之后,还启动了一个定时任务的接口,主要是由于用户上传文件之后,会残留临时文件,我们需要把他定期清理掉。
36-45行:优雅启停,如碰上意外情况关闭服务时,不会一下子“秒挂”服务,会依次处理相关任务,好让进程有所反应。
以上已经完成了文件解耦的工作,移动到routes目录,接下来去完成具体的业务实现:
业务逻辑的实现
coverter的路由跟上一节我进行了变动,我重新整理了需求,上一节我只限制webp转换img格式,格式是固定的,现在我们的需求改为特定的四种格式png、jpg、jpeg、webp转换为特定的三种格式jpg、png、webp。我想这几种格式已经覆盖大部分的需求了。
import { Hono } from "hono";
import { zValidator } from "@hono/zod-validator";
import { ImageConverterService } from "../../../core/services/image-converter.service";
import { z } from "zod";
const converterRouter = new Hono();
const converterService = new ImageConverterService();
// 支持的格式
const allowedInputTypes = [
"image/png",
"image/jpeg",
"image/jpg",
"image/webp",
];
const allowedTargetFormats = ["jpg", "png", "webp"];
// 定义 Zod 验证 schema
const schema = z.object({
file: z
.instanceof(File, { message: "请上传有效文件" })
.refine((f) => allowedInputTypes.includes(f.type), "仅支持png、jpg、jpeg、webp格式")
.refine((f) => f.size < 5 * 1024 * 1024, "文件大小不能超过5MB"),
targetFormat: z.string().refine((val) => allowedTargetFormats.includes(val), "目标格式不合法"),
});
converterRouter.post(
"/",
zValidator("form", schema),
async (c) => {
const { file, targetFormat } = c.req.valid("form");
try {
const buffer = Buffer.from(await file.arrayBuffer());
const convertedUrl = await converterService.convert(buffer, targetFormat as "jpg" | "png" | "webp");
return c.json({
original: file.name,
convertedUrl,
});
} catch (error) {
return c.json({ err: error instanceof Error ? error.message : "文件处理失败" }, 500);
}
},
);
export default converterRouter;
17-23行:使用了zod作为校验器,hono的风格是定义一个schema作为对象来校验。我们没有通用的校验器,但是单独自定义的校验还是必要的。
25-40行:常规的post接口处理,32行访问了对应的service业务处理。
接下来做删除文件的route:
import { Hono } from "hono";
import { CleanupService } from "../../../core/services/cleanup.service";
import { success } from "zod/v4";
const cleanupService = new CleanupService();
const cleanupRouter = new Hono();
// 启动定时清理
cleanupRouter.post("/start", (c) => {
try {
cleanupService.startCleanupService();
return c.json({ message: "Cleanup service started", success: true }, 200);
} catch (error) {
return c.json(
{ message: "Cleanup service failed to start", success: false },
500,
);
}
});
cleanupRouter.get("/status", (c) => {
try {
cleanupService.startCleanupService();
return c.json({ message: "Cleanup service started", success: true }, 200);
} catch (error) {
return c.json(
{ message: "Cleanup service failed to get status", success: false },
500,
);
}
});
// 停止
cleanupRouter.post("/stop", (c) => {
try {
cleanupService.stopCleanupService();
return c.json({ message: "Cleanup service stopped", success: true }, 200);
} catch (error) {
return c.json(
{ message: "Cleanup service failed to stop", success: false },
500,
);
}
});
// 手动触发
cleanupRouter.post("/manual", (c) => {
try {
cleanupService.manualCleanup();
return c.json({ message: "Cleanup service triggered", success: true }, 200);
} catch (error) {
return c.json(
{ message: "Cleanup service failed to trigger", success: false },
500,
);
}
});
export default cleanupRouter;
清理的代码就比较公式化了,含常规的启停,这里返回格式还可以进一步的封装,中大型项目还需要额外实现。
接下来我们进入services,移动到core目录下:
image-converter和上一节内容有所差异,主要是扩展了多种格式。
import { randomUUID } from "node:crypto";
import { promises as fs } from "node:fs";
import sharp from "sharp";
import path from "node:path";
export class ImageConverterService {
private readonly outputDir = path.join(process.cwd(), "public/converted");
constructor() {
// 确保输出目录存在
fs.mkdir(this.outputDir, { recursive: true });
}
/**
* 通用图片格式转换
* @param fileBuffer 上传文件的buffer
* @param targetFormat 目标格式 jpg/png/webp
* @returns 转换后的文件路径,相对于public
*/
async convert(fileBuffer: Buffer, targetFormat: "jpg" | "png" | "webp"): Promise<string> {
try {
const ext = targetFormat === "jpg" ? "jpg" : targetFormat;
const outputFilename = `${randomUUID()}.${ext}`;
const outputPath = path.join(this.outputDir, outputFilename);
let sharpInstance = sharp(fileBuffer);
if (targetFormat === "jpg") {
sharpInstance = sharpInstance.jpeg({ quality: 80 });
} else if (targetFormat === "png") {
sharpInstance = sharpInstance.png({ quality: 80 });
} else if (targetFormat === "webp") {
sharpInstance = sharpInstance.webp({ quality: 80 });
} else {
throw new Error("不支持的目标格式");
}
await sharpInstance.toFile(outputPath);
return `/converted/${outputFilename}`;
} catch (err) {
throw new Error(
`convert failed: ${err instanceof Error ? err.message : String(err)}`,
);
}
}
/**
* 清理临时文件
*/
async cleanup(fileUrl: string) {
const filename = path.basename(fileUrl);
const flePath = path.join(this.outputDir, filename);
try {
await fs.access(flePath);
await fs.unlink(flePath);
} catch (error) {
console.error(`delete file failed: ${error}`);
}
}
/** 清理已转换的文件 */
async cleanupConvertedFiles() {
try {
const files = await fs.readdir(this.outputDir);
const convertedFiles = files.filter((file) => file.endsWith(".converted.jpg"));
for (const file of convertedFiles) {
const filePath = path.join(this.outputDir,file);
try {
await fs.unlink(filePath)
} catch (error) {
console.error(`delete file failed: ${error}`);
}
}
} catch (error) {
console.error(`cleanup converted files failed: ${error}`);
}
}
/** 获取已转换文件的数量 */
async getConvertedFilesCount() :Promise<number>{
try {
const files = await fs.readdir(this.outputDir);
return files.filter((file) => file.endsWith(".converted.jpg")).length;
} catch (error) {
console.error(`get converted files count failed: ${error}`);
return 0;
}
}
}
这里的大体思路是将上传的文件转换之后,形成的临时文件加一个标记,或者移动到临时文件路径下,再通过cleanup服务定期清理。
这里讲个题外话,现在AI能力很强,大多数的业务代码AI都能做,我的文章讲一些产品、设计、架构上的思路,这是由于AI的编码能力很强大,但是对于一些噪音和具体的需求、产品思维的实现实际是欠缺的,现在市面上诞生了提示词工程师,专注于优化AI的提示词;如果我们从系统观念的角度出发思考,辅以AI工具,我认为是一个有效的转型方向。
继续实现最后一步的清理文件业务:
import { ImageConverterService } from "./image-converter.service";
export class CleanupService {
private readonly imageConverterService: ImageConverterService;
private cleanupInterval: NodeJS.Timeout | null = null;
private readonly CLEANUP_INTERVAL_MS = 1000 * 60 * 60 * 24; // 24小时
private readonly MAX_FILE_AGE = 2 * 60 * 60 * 1000; // 2小时
constructor() {
this.imageConverterService = new ImageConverterService();
}
/**
* 启动定时清理服务
*/
startCleanupService() {
console.log("start cleanup service");
this.performCleanup();
// 设置定期清理任务
this.cleanupInterval = setInterval(() => {
this.performCleanup();
}, this.CLEANUP_INTERVAL_MS);
console.log(
`cleanup service started, cleanup interval: ${this.CLEANUP_INTERVAL_MS}ms`,
);
}
/**
* 清理操作
*/
private async performCleanup() {
try {
const beforeCount =
await this.imageConverterService.getConvertedFilesCount();
if (beforeCount > 0) {
await this.imageConverterService.cleanupConvertedFiles();
const afterCount =
await this.imageConverterService.getConvertedFilesCount();
console.log(
`cleanup completed, before: ${beforeCount}, after: ${afterCount}`,
);
} else {
console.log("no converted files to cleanup");
}
} catch (error) {
console.error(`cleanup failed: ${error}`);
}
}
/**
* 停止定时清理服务
*/
stopCleanupService() {
if (this.cleanupInterval) {
clearInterval(this.cleanupInterval);
this.cleanupInterval = null;
console.log("cleanup service stopped");
}
}
/**
* 手动清理
*/
async manualCleanup() {
try {
await this.performCleanup();
} catch (error) {
console.error(`manual cleanup failed: ${error}`);
}
}
getStatus(){
return{
isRunning: this.cleanupInterval !== null,
interval: this.CLEANUP_INTERVAL_MS,
nextCleanup: this.cleanupInterval ? new Date(Date.now() + this.CLEANUP_INTERVAL_MS).toISOString() : null,
}
}
}
同样的,业务方面也不复杂,调用的文件操作已经实现过了,正常调用即可。
总结
今天这个重构过程大多数代码都是用AI实现的,正确率和效率都还是不错,我在其中担任的工作是以工程化的思想让AI打工。
当下的IT技术发展,工程化、计算机基础、架构思维,越来越重要,这对新人来说是一种考验,因为这些能力本就是在实践中锻炼,没有这方面的阅历容易陷入夜郎自大的陷阱里。
同时对我们这种 “老人”也是一种考验,若是面向独立开发、面向未来,高效能利用AI是很有必要的,这段时间我经常看别人的创业故事和独立开发日记,那些具有产品思维的开发或者具有开发能力的产品,在这样的AI浪潮下勇立潮头。
而传统的💩代码由于其历史的业务原因,倾向于用外包或者现有工程师维护,他们的精力成长性正在逐步损耗,在AI的效率革命之下,可能会受到一定冲击,而这在短期内可能不会看到。
这一节解耦之后,下一节在前端层面加入i18n的配置,因为我们的工具站以英文站为主。现在Vercel的路径能访问,但是功能受限,后续完成私有服务器部署之后再贴地址。代码的远程仓库如下Hono.js实现文件转换
感谢阅读,拜拜~



